The Warewolf Syntax is purely used for referencing data. There are no functions that can be executed using the language. To manipulate and transform the data, we use the system tools and mashups of services.
The syntax allows us to use our data as and when it is needed.
Data is held in memory for as long as the service or microservice (workflow) is executing.
There are a few rules you need to follow when defining your variables / [[Syntax]] for the Variable List:
- Variables are defined by using [[ and ]] square braces.
- Variables are CaSe SensistiVe. So [[this]] does not equal [[This]].
- Variables cannot have spaces in their names. So [[First Name]] is not allowed.
- Variables are made up of alphanumeric characters as well as dashes (-) and underscores (_).
- Variables must start with an alphabetical character.
- Objects must be prefixed with an @ symbol.
- If your variable is red in the input area, then it has not yet been added to the variable list, or it is in an error state. Check that it is not duplicated and that these rules are followed.
- Nested braces are dealt with as they are typed at design time and not as they appear at run time. So [[[[Part]]]] will evaluate twice. [[Part]] (where the value is “[[Piece]]”) will evaluate only once.
- Variables are Unique per Service/Variable List.
We break data down into Scalars, Recordsets and Objects. Scalar refers to an individual piece of information while Recordsets refers to repeated or tabular information, and an object refers to data that represents an object, for example, from JSON or an object returned from the call of a method using the DotNetDLL tool.
Scalars
The notation for a Scalar variable is [[VariableName]]. A use case could be [[Firstname]] = Bart and [[Surname]] = Simpson
If an input for another service required the format “Surname, Firstname” then we would simply input like so “[[Surname]], [[Firstname]]” which would be the equivalent of “Simpson, Bart”
Recordsets
The notation for a Recordset variable is [[Recordset(n).Field]].
n refers to the index of the recordset
Recordset or repeating variables can have a number of different uses.
Given we have the following recordset data in the examples below:
[[Family(1).Name]] = Homer [[Family(1).Surname]] = Simpson
[[Family(2).Name]] = Marge [[Family(2).Surname]] = Simpson
[[Family(3).Name]] = Lisa [[Family(3).Surname]] = Simpson
[[Recordset()]] – no Field Name
- As Input: Only ever used when a tool needs to know a Recordset Name to perform work on, like Count Records Tool or For Each Tool.
- Example:
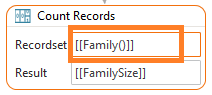
- As Result: Never
[[Recordset(n).Field]] – n Exists
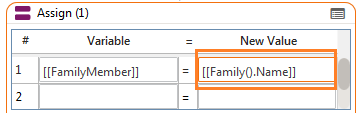
- As Input: Behaves exactly like a Scalar. This notation is used when getting information out of a recordset at a particular index. If n = 3, then the value of the field in row 3 will be used.
- Example:
![Assing Tool [[FamilyMember]]- Used in Warewolf](http://warewolf.io/knowledge-base/wp-content/uploads/2016/05/var1.png) [[FamilyMember]] would now = Simpson, Lisa
[[FamilyMember]] would now = Simpson, Lisa
- As Result: Behaves exactly like a Scalar. The value of the variable will be overwritten with the new output value.
- Example:
![Assign Tool - Used in Warewolf to show [[Family(3).Surname]]](http://warewolf.io/knowledge-base/wp-content/uploads/2016/05/var2.png)
[[Recordset(n).Field]] – n Doesn’t Exist
- As Input: An index that does not exist has a Null value, so an error is returned.
- Example:
![[[FamilyMember]] used to show family surname number 4](http://warewolf.io/knowledge-base/wp-content/uploads/2016/05/var3.png) Will error at run time if the data is as per above.
Will error at run time if the data is as per above.
- As Result: Specifying an index that does not exist, will append NULL data up to that index and then the Result at that index – effectively creating the index.
[[Recordset().Field]] – no Index
- As Input: Assumes the last index and inserts the value at that index. This is so you don’t have to track the last index.
- Example:
 [[FamilyMember]] would now = Lisa.
[[FamilyMember]] would now = Lisa.
- As Result: Behaves exactly like a Scalar. Appends one new record to the Recordset from the last index.
- Example:
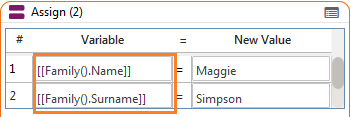 [[Family(4).Name]] would now = Maggie and [[Family(4).Surname]] would now = Simpson.
[[Family(4).Name]] would now = Maggie and [[Family(4).Surname]] would now = Simpson.
[[Recordset(*).Field]]
- As Input: Will execute each and every index in the Recordset.
- Example:
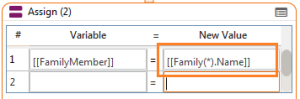 [[FamilyMember]] would now = Lisa (Each record executed so the last record would be the remaining one).
[[FamilyMember]] would now = Lisa (Each record executed so the last record would be the remaining one).
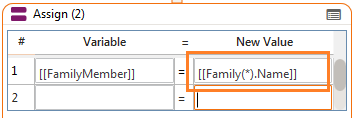
- As Result: For every execution, the result will be written to the Recordset starting at index 1 until there are no more results. If indexes already exist then data at that index will be overwritten.
- Example:
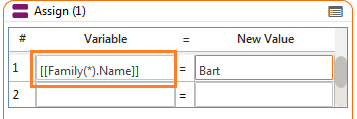 Every Name in the Family recordset will be Bart.
Every Name in the Family recordset will be Bart.
The Language can also be used in a “concatenation” type way, so for example
“[[Family(*).Surname]] – [[Family(*).Name]] | “ in a single field will give you:
“Simpson – Homer | ”
“Simpson – Marge | “
“Simpson – Lisa | “
Syntax Summary
| [[Rec (*).Field]] | [[Rec ().Field]] | [[Rec(n).Field]] – n Exists | [[Rec(n).Field]] – n Doesn’t Exist |
| Input All | Last record | Record at index “n” | NULL |
| Output All with overwrite | Append from last | Record at index “n” | Append up to “n” |
Objects
The notation for an Object variable is either [[Object.Property]] or [[Object(n).Property]] n refers to the index in an array of objects.
Given we have the following object data in the examples below:
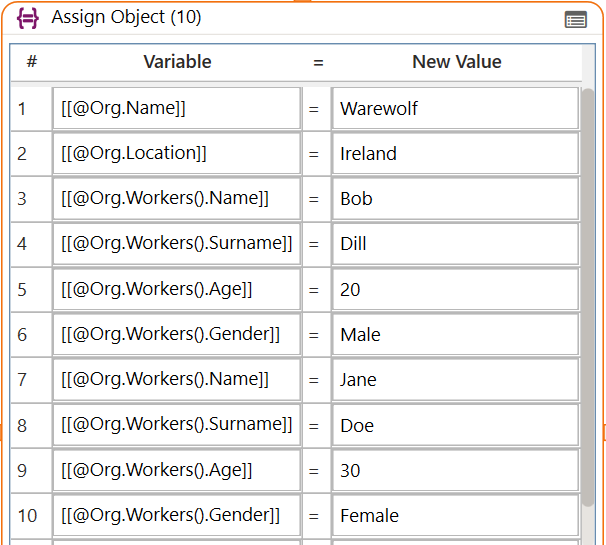
[[@Org.Name]] = Warewolf [[@Org.Location]] = Ireland
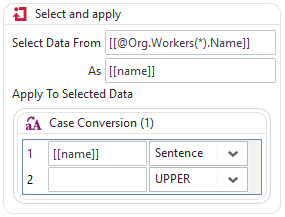
[[@Org.Workers(1).Name]] = Bob [[@Org.Workers(1).Surname]] = Dill [[@Org.Workers(1).Age]] = 20 [[@Org.Workers(1).Gender]] = Male
[[@Org.Workers(2).Name]] = Jane [[@Org.Workers(2).Surname]] = Doe
[[@Org.Workers(2).Age]] = 30 [[@Org.Workers(2).Gender]] = Female
In the case of accessing non array properties, behaviour is the same as scalars and in the case of array’s the behaviour is the same as recordsets. The main difference being that properties can be object themselves which allows for multi-level data structures.
At present only two tools support object data natively. The Assign Object tool is used to setup objects or directly manipulate the data in properties.
The other tool is the Select and Apply tool which will allow the extraction of the data into an alias that can then be used in any tool that can then update the property value.
Not what you were looking for? Ask our expert users in the Community Forum.